Announcing the Proof-of-Diligence (PoD) algorithm: A method of modeling trust and maintainability in open source ecosystems
The OSS Trust Graph is an implementation of the Proof-of-Diligence algorithm created at Stacklok. Proof-of-Diligence (PoD) provides a robust mechanism to model trust, quality and maintainability in open source ecosystems. This blog post provides details on the reasoning behind the algorithm, how it is implemented, and how it can be used.
In November 2023, Stacklok introduced Trusty, a free-to-use service that utilizes source-of-origin code provenance and data-science algorithms to quantify the supply chain risk of open source projects and help developers choose safer, more trustworthy dependencies. Today, we’re introducing the OSS Trust Graph (available now in private beta—sign up here), an implementation of the Proof-of-Diligence algorithm created at Stacklok. Proof-of-Diligence (PoD) provides a robust mechanism to model trust, quality and maintainability in open source projects. This blog post provides details on the reasoning behind the algorithm, how it is implemented, and how it can be used.
Introduction
Open source software (OSS) is characterized by its collaborative and decentralized development model, engaging a global and diverse community. These communities operate asynchronously and non-linearly, reflecting the inherently open nature of OSS that encourages anyone to contribute, irrespective of their affiliation with recognized institutions, corporations or global locality. Contributors often adopt pseudonyms or usernames on cloud-based code-hosting platforms like GitHub or GitLab, preserving a level of anonymity while participating in these digital ecosystems. An intrinsic element of OSS communities is understanding the quality of an OSS project, which is critical when developers and organizations choose to integrate OSS into their own projects. In turn, many OSS projects depend on each other, creating a complex graph of thousands of transitive dependencies.
Computers are very good at establishing trust between machines when it comes to cryptography-based verification, but they struggle to grasp the more social, human aspects of trust. Trust within a social context is more nuanced and is typically the domain of people, more than machines.
In everyday life, we often rely on a construct known as a “social graph,” both in the digital and physical world, to make decisions about whom to trust. For example, when hiring a tradesperson, I'm more likely to trust them if someone from my immediate social network recommends them. This could be because they have a direct relationship with the tradesperson, such as a family member, or they know them indirectly through another trusted acquaintance.
The concept of a social graph, although less obvious, also applies when developers or organizations select open source software dependencies. They may look at how popular a software project is by checking how many times it's been downloaded, the number of social likes it has on the code hosting platform, and the profiles and past contributions of the developers involved. They might also visit forums like StackOverflow or seek advice from a LLM (large language model), or they might referrence what other similar projects are using. They attempt to derive a signal of quality from others to help them form their choices. An outlier to this, might be manual review of every line of code within a dependency, but that is far more likely the exception, than the rule.
However, this method of assessing the quality and safety of open-source software projects has its drawbacks. First, it doesn’t scale well and lacks a standard, agreed-upon consensus or approach. Secondly, it’s vulnerable to deceptive practices, such as artificially boosting a project’s popularity, or unintentional hallucinated outputs from a LLM. Typically, security companies measure a project’s safety by counting the number of known common vulnerabilities and exposures (CVEs).
Yet, as previously discussed, CVEs are not always reliable indicators of safety. Very few CVEs are exploitable in the first place, and more sophisticated attacks often go undetected by standard CVE scanners. An attack becoming more prolific and seeing a marked increase is where an individual offers to take over the maintenance of a project and then proceeds to introduce a backdoor (as with the recent XZ attack). The importance of the people is becoming increasingly recognized within the software industry.
Proof-of-Diligence Algorithm
We seek to solve many of these aforementioned problems using a new Algorithm we have named Proof of Diligence (PoD). PoD is a means of measuring and quantifying the relationships between open source contributors and open source projects. We further combine Proof of Diligence (PoD) with foundational trust systems such as sigstore or Stacklok’s historical provenance, to ensure the data we use to compute scores is legitimate. PoD also benefits from its ingested data being derived from git, which possesses an immutable, timestamped and distributed architecture.
Open source communities intrinsically possess an untapped proof-of-diligence based on contributions, quality code curation, and meritocracy. This proof is situated upon, but not limited to, the effort required to receive (review and scrutinize code) and contribute (develop) useful, quality code (a bug fix or a feature that provides utility).
We effectively have a two-way signal. When a contributor with a track record of successful engagements with well-regarded quality projects contributes to another project, it strongly indicates that the second project very likely meets a high standard of quality itself. Conversely, if a reputable and popular project accepts contributions from an individual, it suggests that the contributions—and by extension, the contributor—are of high quality and demonstrate diligence and utility in their work.
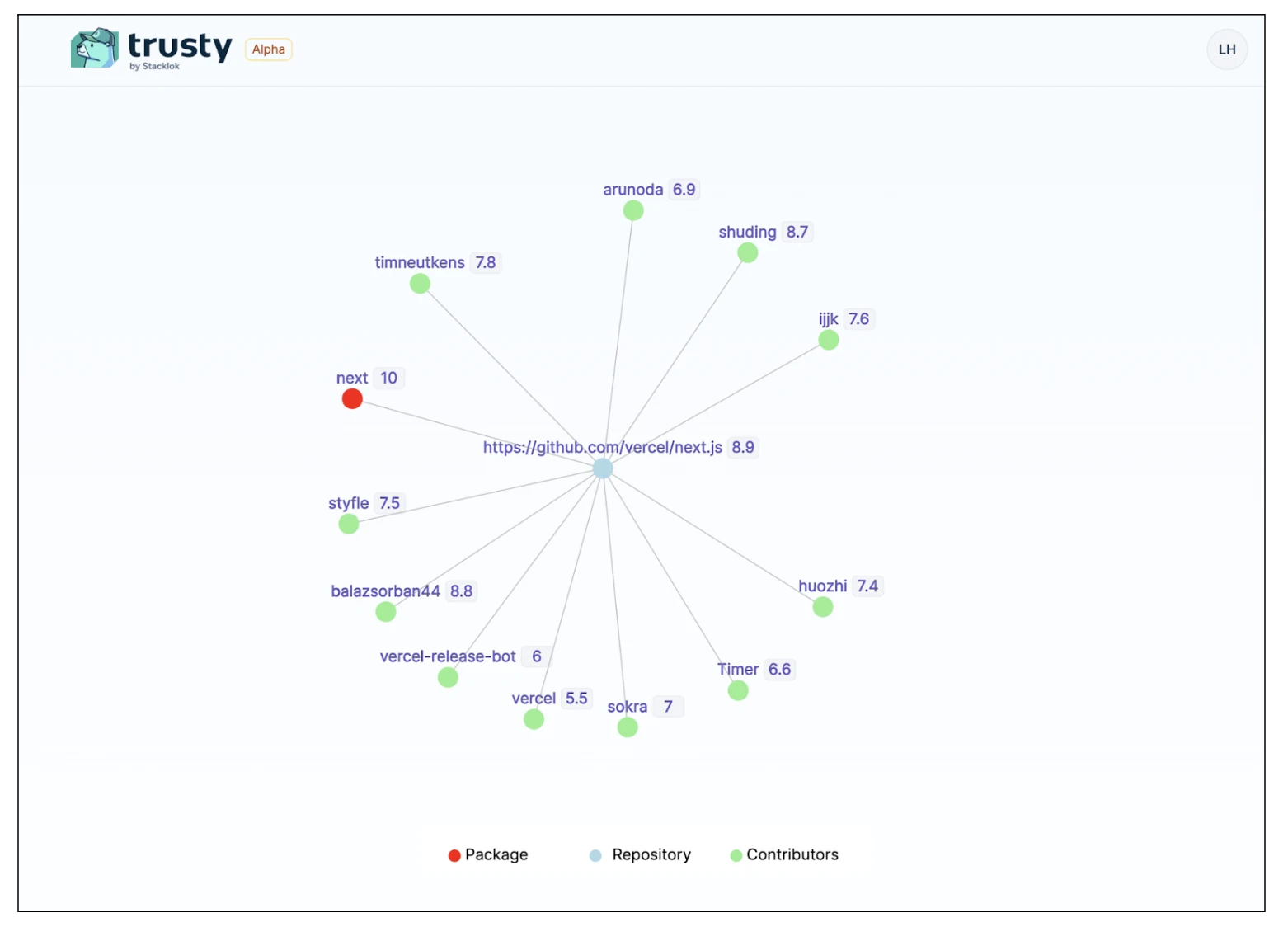
Above: Prototype of the Package Graph view of the next.js project
So the open source ecosystem effectively records an inherent proof-of-diligence that is intrinsic to the ecosystem's flow of trust in an open and transparent manner. Developers invest significant time to produce quality code and/or documentation: code that passes continuous integration tests, code that is easy to read and review by others, and, most obvious of all, code that provides meaningful value to a project (fixes a bug, adds a useful feature).
This long-term curated effort is captured within a proof-of-diligence based graph through a series of interconnected nodes, in the form of developers, repositories and packages. This is a type of consensus algorithm that is incredibly difficult and challenging to game, which is why it has applicable utility to software security, most notably software supply chain security. It also respects pseudonymity, an important ethos to many OSS communities. PoD allows for individuals to be measured based on their contribution footprint and not on their real life identity or affiliation with recognized institutions or corporations.
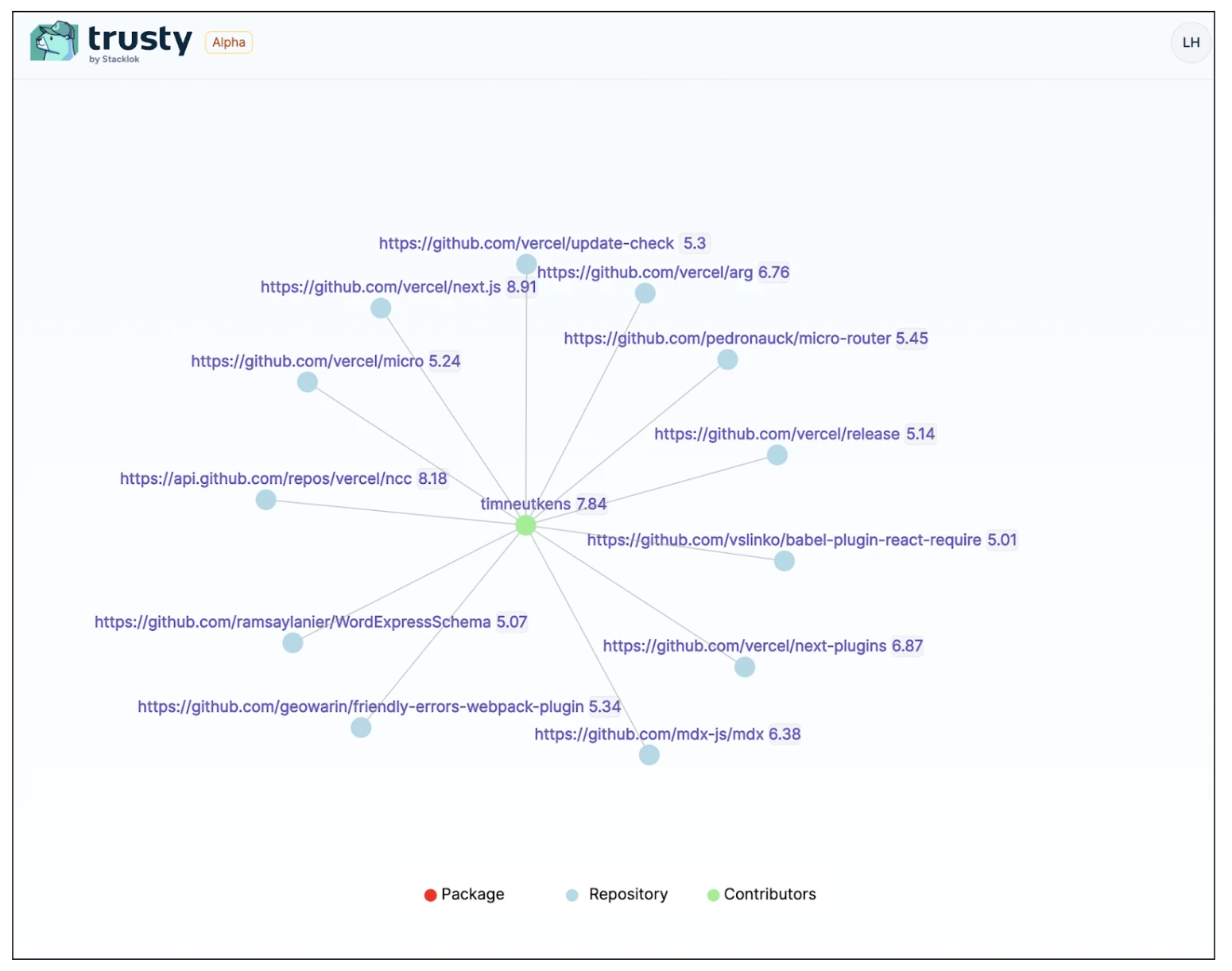
Above: Prototype of the Contributor Graph view of a next.js contributor
Furthermore, projects are often presented as a package, which typically has dependency on other packages. The quality of a package often depends on the other packages (in the form of a dependency). Each of these projects/dependencies can recursively have additional package dependencies, thus creating a transitive structure. All of these packages undergo a lifecycle where they elevate or decrease in popularity and eventually go into maintenance. The Proof-of-Diligence protocol will be capable of measuring the lifecycle of a software package and the influence of its entire dependency chain.
Methodology and Application of PoD
PoD utilizes a network graph, capable of propagating trust and establishing a final PoD score. The graph contains three types of nodes: project, contributor (aka developer), and package. The edges in the graph represent the influence relations among these nodes, indicating the direction in which the trust flows. The edges in the graph are weighted where the edge weights represent the strength of influence. Here are the different types of edges.
Project → Contributor: A project influences a contributor’s score.
Contributor → Project: A contributor influences the score of the project.
Project → Package: A project influences the score of a package.
(Dependent) Package → Package: A dependent package influences the score of the parent package.
(Author) Contributor → Package: A package author influences the score of the package.
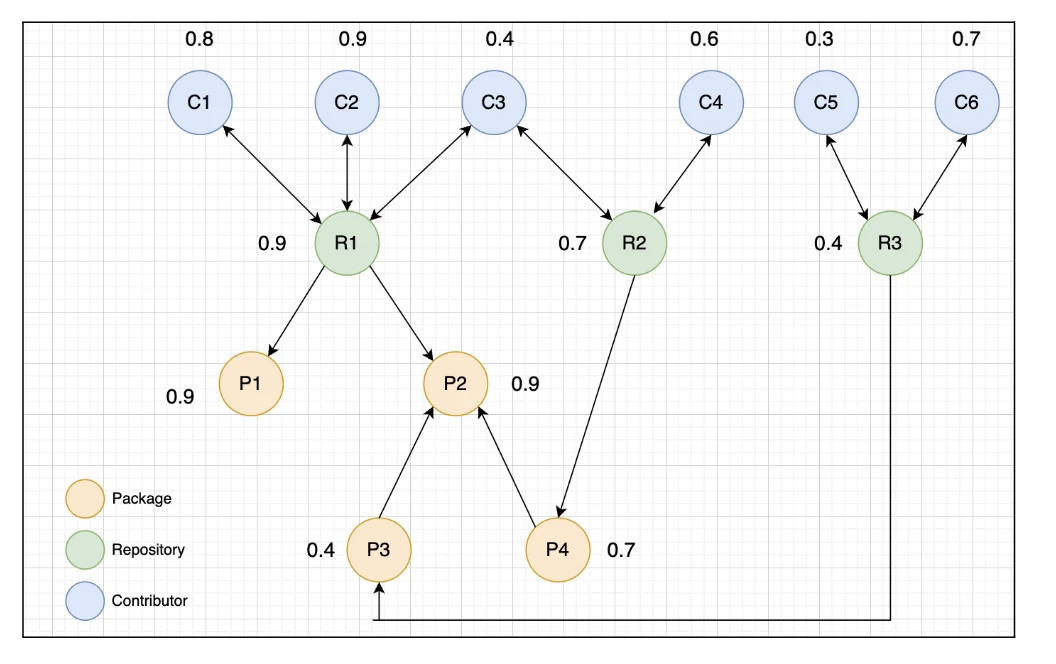
Consider the following mocked example. The numbers shown next to each node are the initial seed scores.
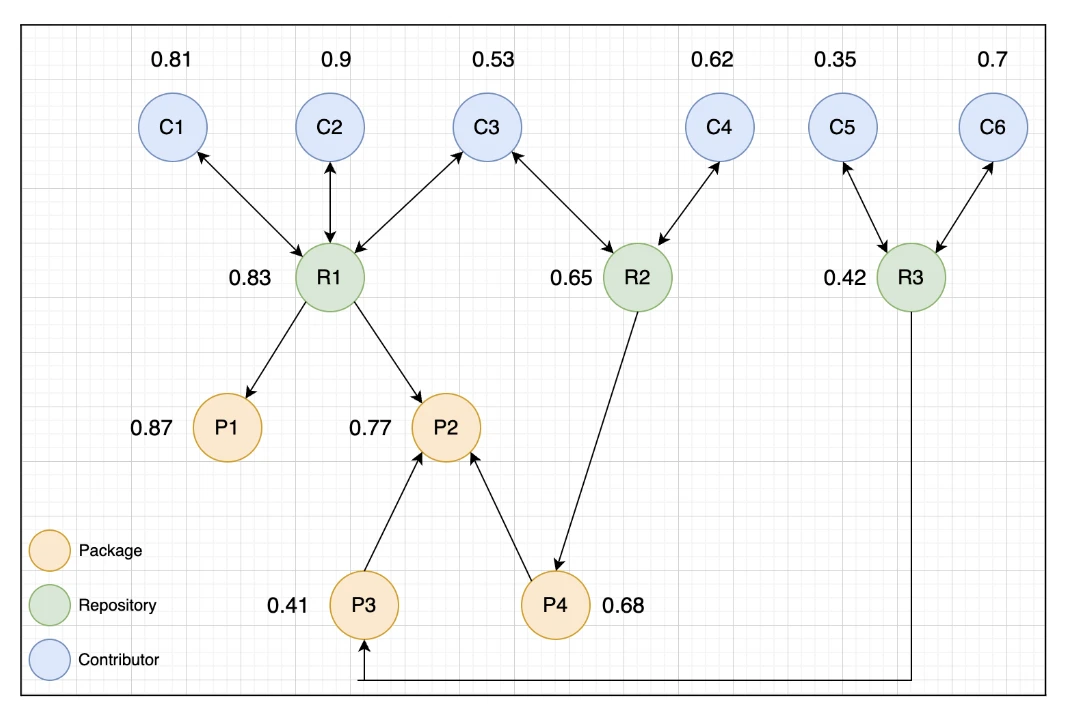
After score propagation, the updated scores may look like below. For example, notice the score of contributor C3 increased from 0.4 to 0.53, since C3 contributed to well reputed repository R1 with initial score of 0.9. Also, the score of R1 computes to 0.83 due to the reverse propagation effect.
Observe that the graph does not have the following edges.
Package → Project edge, that is, a package does not influence the project score.
Package → Contributor edge, that is, a package does not influence the contributor score.
Package → (Dependent) Package edge, that is, a package does not influence the dependent package score.
The extent of influence of a contributor on a project depends upon the recency of their contribution. A contributor with a more recent contribution should influence a project more than a contributor with an older contribution. The weight of the edge between a contributor and a project captures such extent of influence.
With the PoD Algorithm, we compute a score for each of the nodes in the graph in two steps.
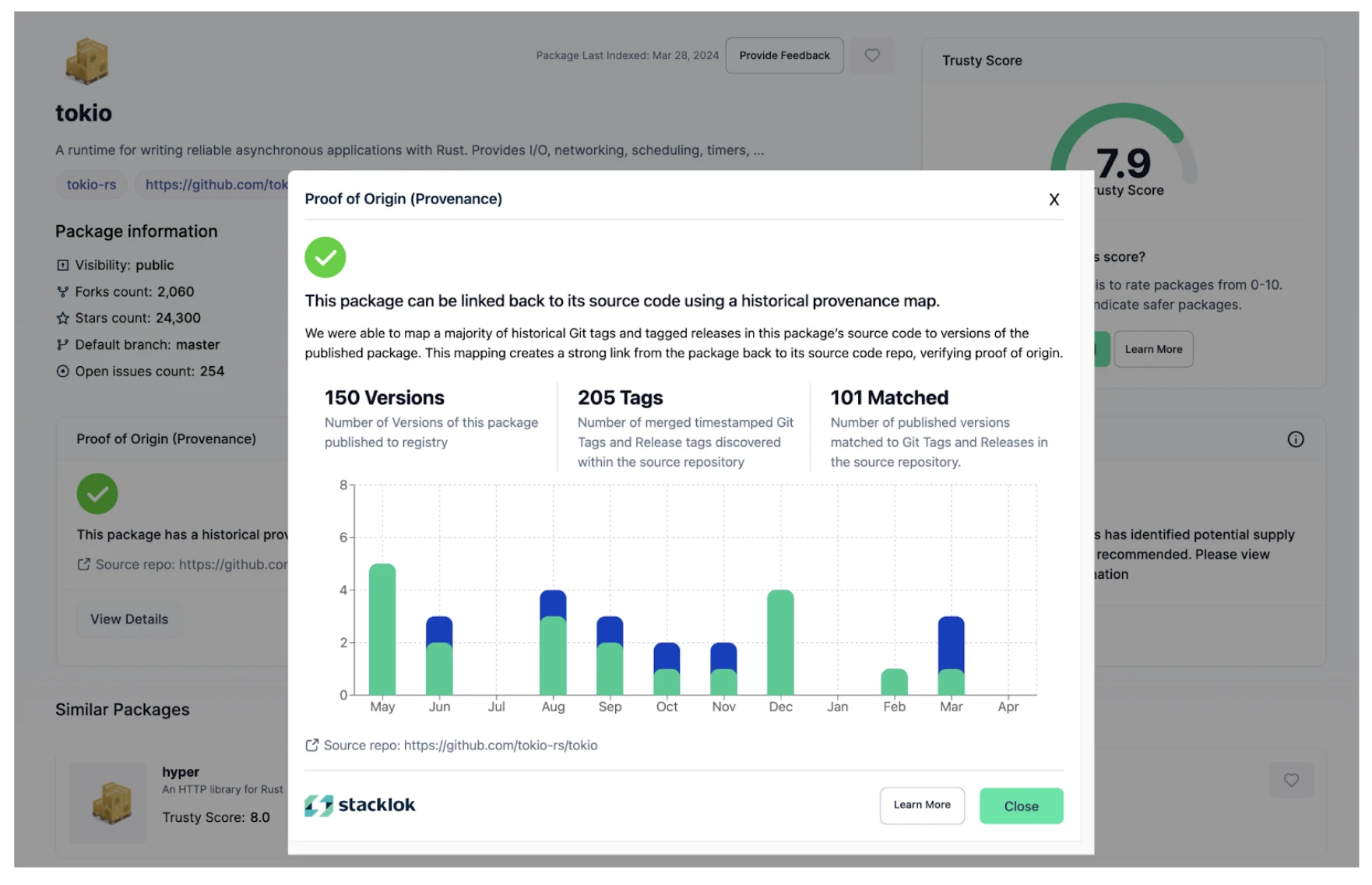
Firstly, when constructing the OSS Trust Graph, we compute a seed score, using Trusty’s existing scoring models. The metrics used for the score are attributes such as the project having a legitimate source of origin claim, using sigstore, or Stacklok’s historical provenance algorithm (in that order). Confirming source of origin and provenance ensures the data we use to calculate the initial seed score is accurate, and not the result of illegitimate representation, such as starjacking.
The table below shows the metrics used for calculating the seed scores for the different nodes and the weights for the different edges.
Node/Edge
Feature
Provenance: Package->Project Edge
Sigstore provenance or Stacklok’s historical provenance
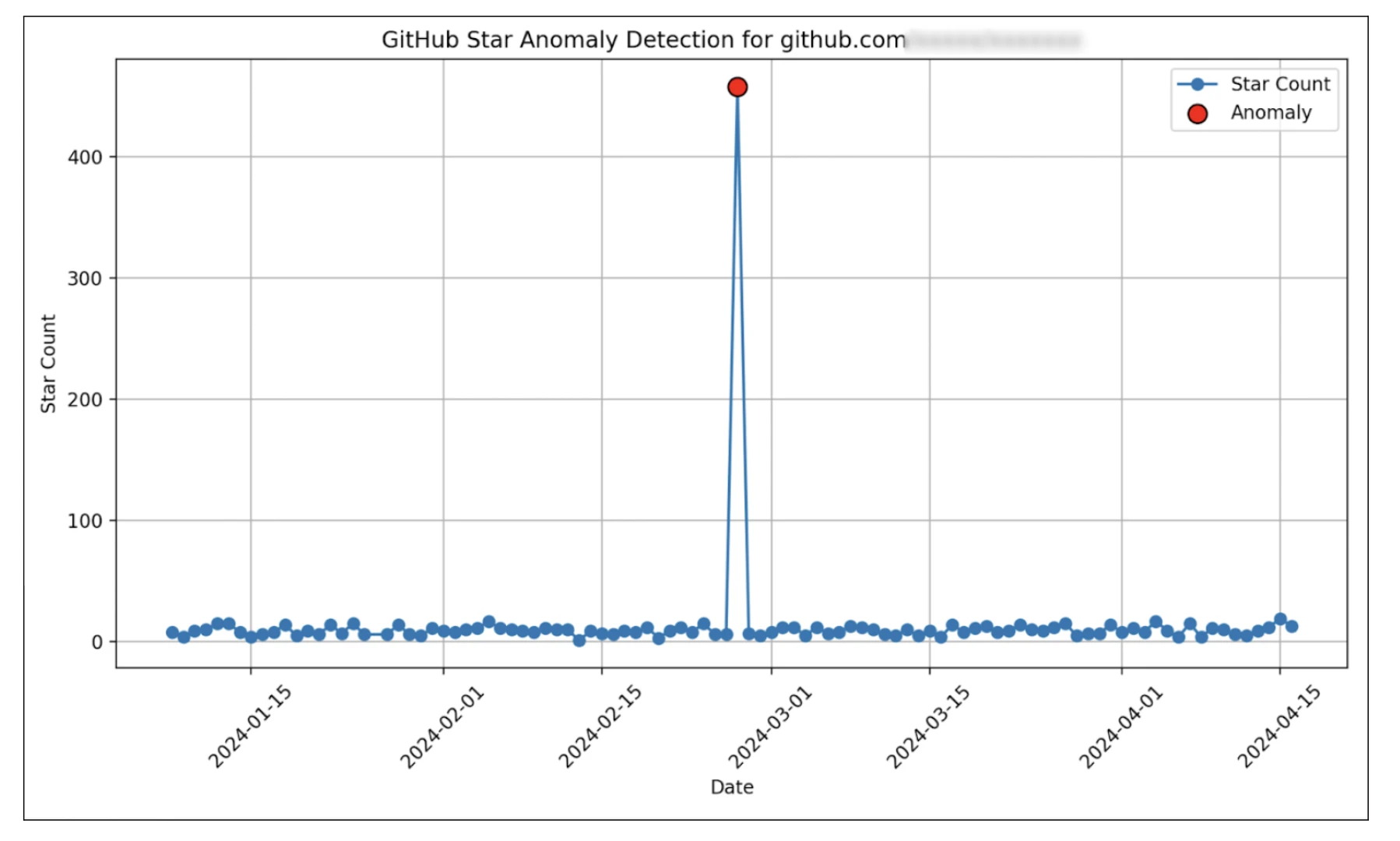
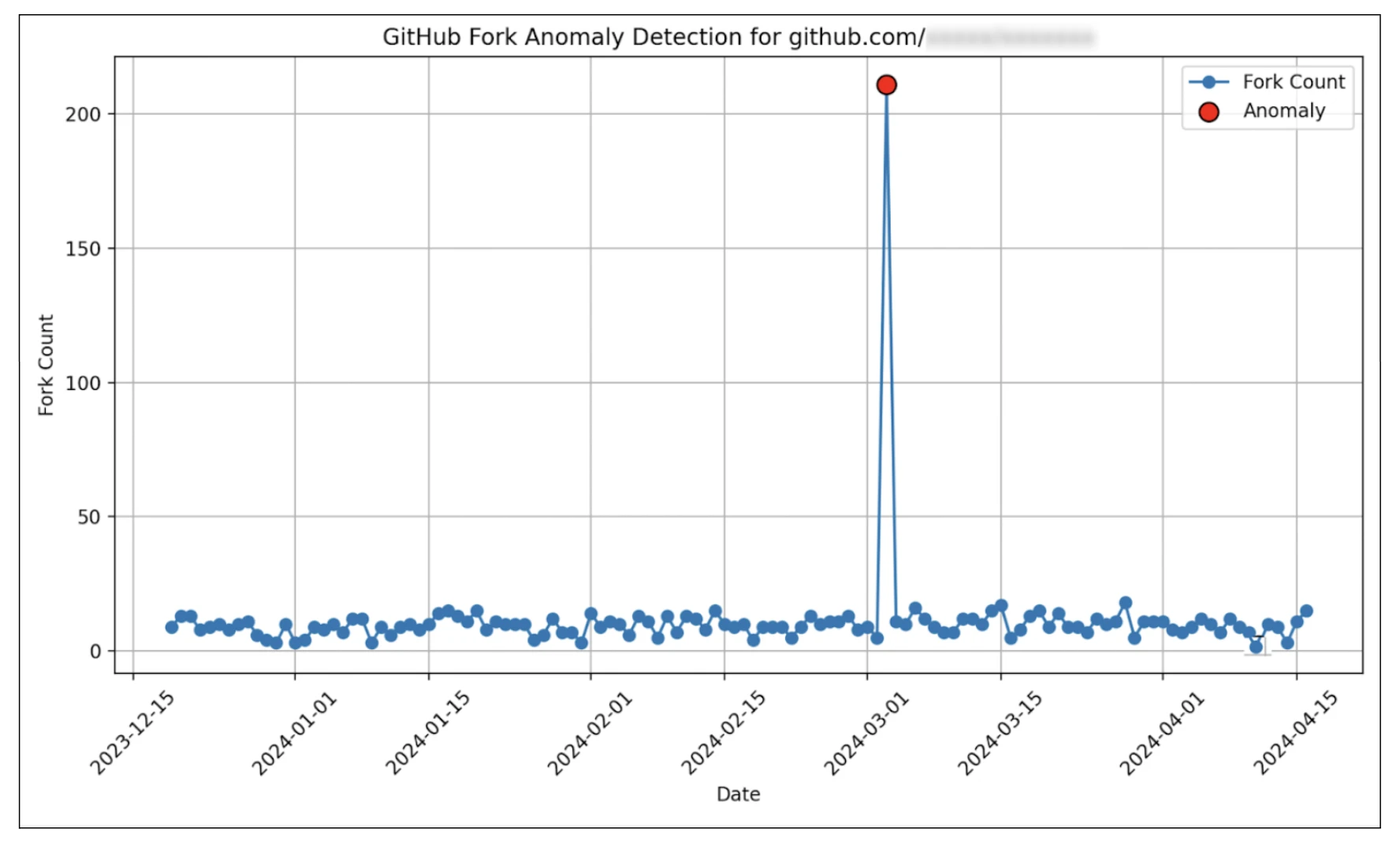
Before using the metrics such as forks, stars and watchers, we verify their authenticity using anomaly detection techniques. See Fraud Protections for further details.
Secondly, we update the seed scores by propagating the trust along all edges in the graph.
Let’s explore several scenarios that demonstrate the trust propagation in the OSS Trust graph.
Scenario One: Project to Contributor Influence
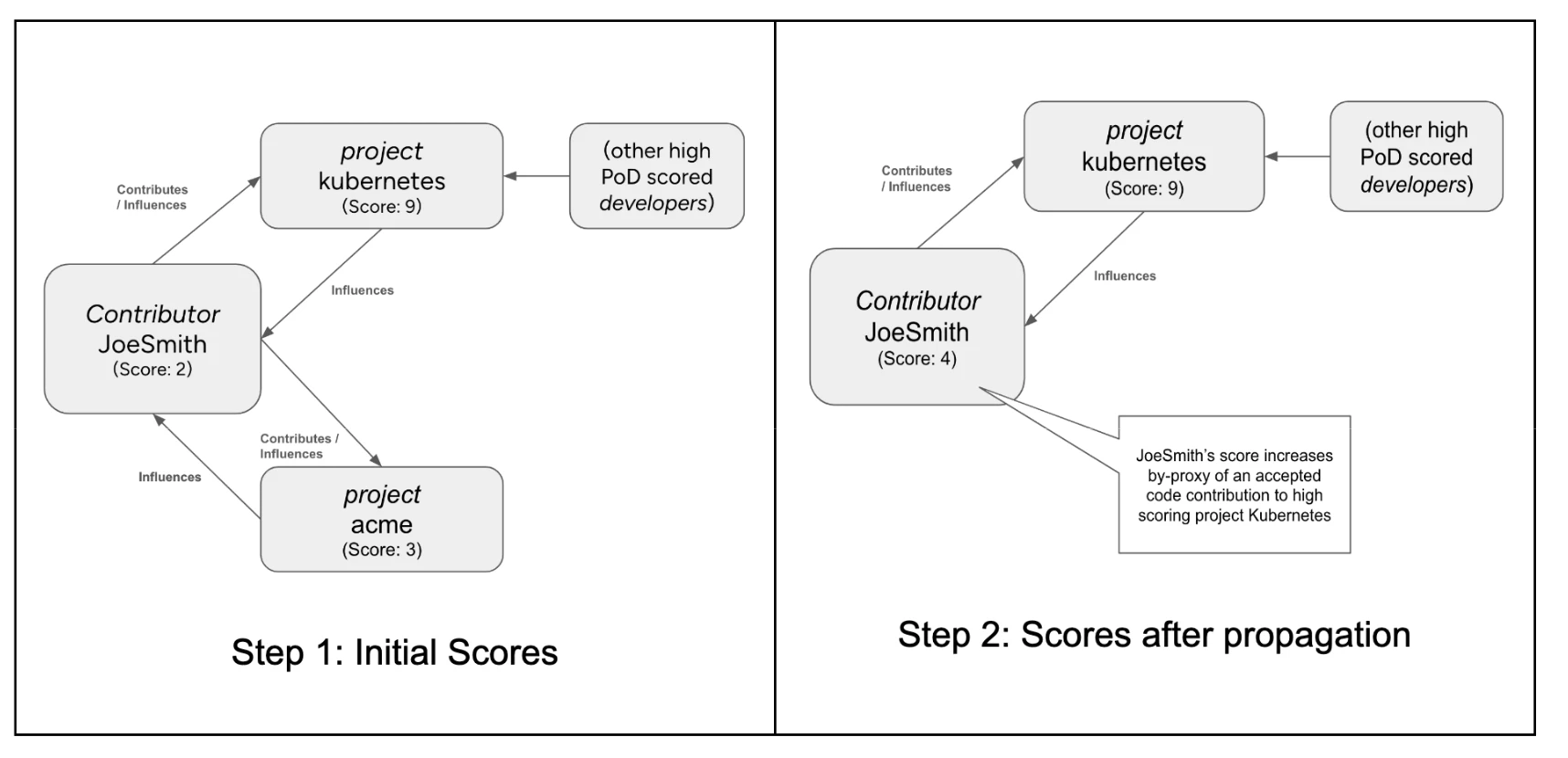
JoeSmith is a relatively new developer, having just started contributing to open source. Their initial computed score is 2.
JoeSmith makes a contribution to the Kubernetes Project with a computed score of 9.
Maintainers of the Kubernetes project review and approve the merging of JoeSmith’s code.
This suggests that JoeSmith produces quality code, is able to pass CI tests and acceptable to the maintainers of a high scoring project (in this case Kubernetes).
After PoD propagation, JoeSmith’s score has increased to 4.
Scenario Two: Project to Contributor Influence
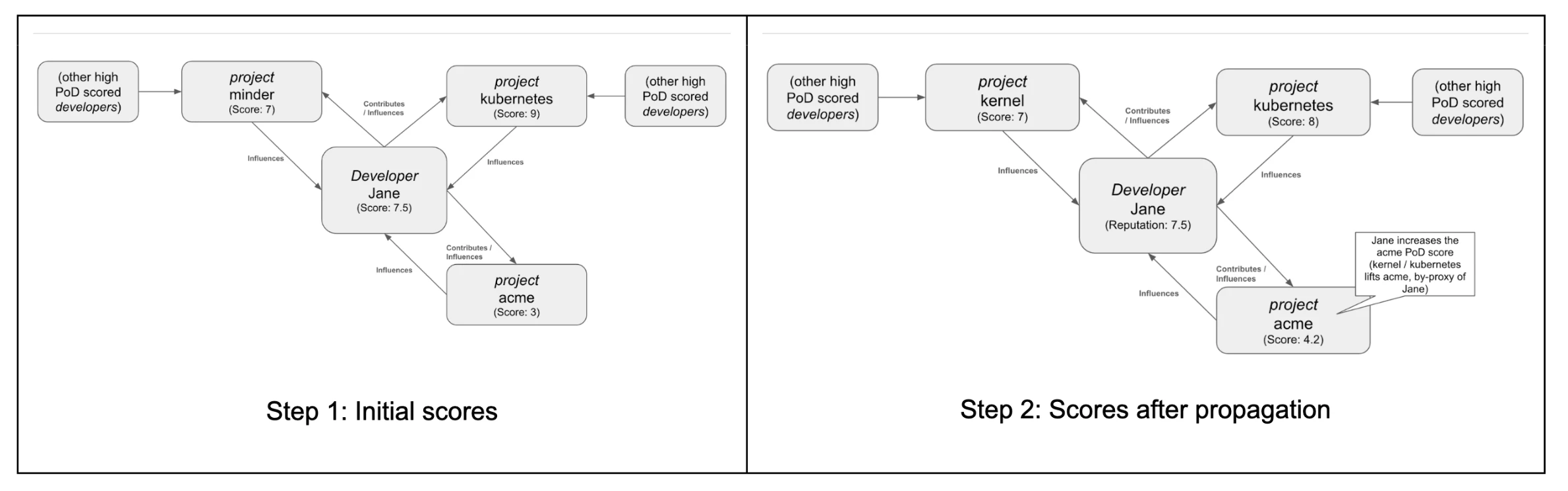
A project called acme exists. It's largely unknown and has low activity. Its initial score is 3.
A user (JaneDoe) contributes to acme. JaneDoe has a high contributor score, based on merged pull requests to high scored projects. JaneDoe’s initial score is 7.5.
This would suggest that JaneDoe sees acme as a quality useful project, sufficient to the point they would take time curating a contribution to the project.
After PoD score propagation, due to JaneDoe’s higher initial score, project acme’s score increases to 4.2.
Scenario Three: Project to Package Influence
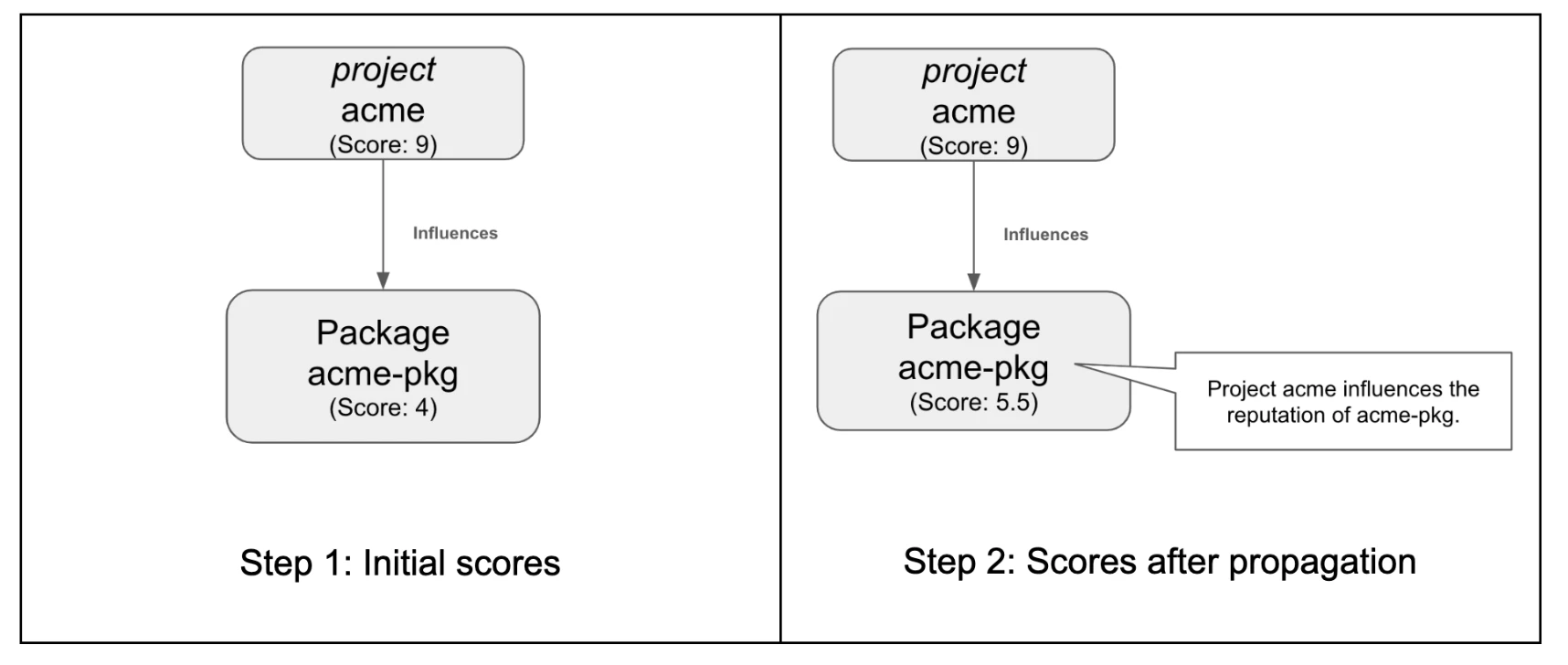
A popular project called acme exists with an initial score of 9.
The package acme-pkg is a newly created package with a low initial score of 4. The score of acme-pkg is influenced by project acme.
After PoD propagation, the score of acme-pkg increases to 5.5. Note that unlike the earlier project-contributor scenarios, in this scenario, project acme’s PoD score remains unchanged since the influence is unidirectional.
Fraud Protections
The Proof of Diligence (PoD) Algorithm is designed to be ‘hard to game’. Developers may curate and build a PoD score over months or years via prolific contribution to OSS projects. A developer will increase their PoD score directly from contributions to projects of value and utility, by writing quality code. We believe this creates an expensive set of conditions to replicate via bots and automation. An attacker cannot game the PoD algorithm just by mass-generating many repositories, along with fake contributor accounts and illegitimate metrics such as GitHub stars, commits and forks. This would only result in many low-scored packages, repositories and contributors propagating low scores to one another.
Provenance
In Stacklok’s coming application of the PoD algorithm and graph within its free-to-use service Trusty, all data provided to the PoD algorithm is vetted for veracity. We require this foundation of truth to establish credible scores. Many security solutions offering OSS package risk scores, do not vet the information they use to calculate scores, making them susceptible to fraudulent data.
We first ensure every package ingested from all ecosystems (Java, Go, Python, Rust, Javascript) has a legitimate claim on the source code repository. We do this using two methods created by stacklok engineers.
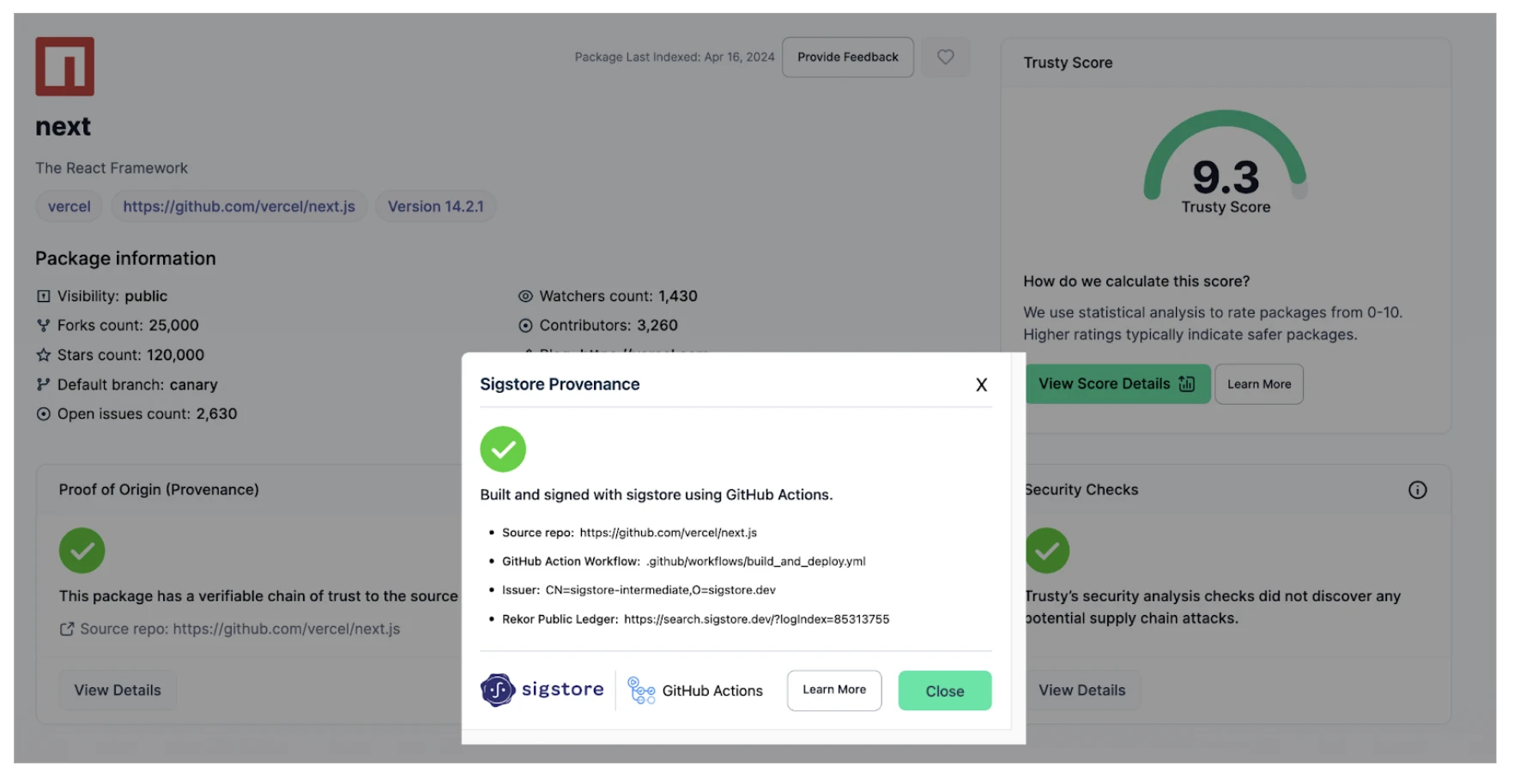
Sigstore Provenance
Sigstore is an open source project started by Stacklok CTO Luke Hinds, to help open source projects sign artifacts and produce a legitimate source of origin claim, or provenance statement. For every package ingested by Trusty, we attempt to map the package to the source repository by validation of a sigstore claim.
This allows us to detect activity such as starjacking, where a project illegitimately claims another project's repository as its own.
Historical Provenance
Historical Provenance is an algorithm developed by Stacklok Data Scientist Nigel Brown. Not all OSS packaging registries have deployed Sigstore. To address this, we created “historical provenance.” Historical provenance consists of mapping Git tags to package versions to verify proof of origin for open source packages.
In the case of Go and the go.sum database, an existing signal of provenance is already available.
Anomaly Detection
The PoD algorithm implemented within Trusty—the “OSS Trust Graph”—over time will also implement univariate and multivariate anomaly detection using techniques such as: isolation forest and one class SVM (Unsupervised Outlier Detection). PoD will employ time-series analysis techniques such as ARIMA (auto-regressive integrated moving average), EWMA (exponential weighted moving average) and FFT (fast Fourier transform) for detecting temporal anomalies. This allows us to detect abnormalities within the context of project metrics such as stars. Quite often, suspicious packages try to inflate their importance by orchestrating bots to provide them with a high count of metrics that indicate popularity. Further, we plan to investigate anomaly detection approaches in dynamic graphs. For example, these approaches will allow us to detect a sudden increase in the number of contributors to a repository which might be indicative of malicious activity.
Potential Future Applications of the PoD Algorithm
Beyond the measure of safety and quality, we have also recognised other utility for the PoD Algorithm.
Identifying open source projects that need support. The score changes of a project can help us detect when a high-contributing maintainer leaves the high-ranking project, leaving it vulnerable to being abandoned and to a hostile takeover. Likewise, the Trust graph can help identify high-ranking projects with a low number of high-ranking maintainers that could benefit from additional support and funding.
Identifying malicious activity. We can’t say with confidence that the PoD Algorithm would have uncovered the XZ vulnerability, but we believe it’s a step in the right direction. We know that the hostile actors’ introduction of many relatively unknown “sock puppet” accounts would have driven down the ranking of the project. While there would be a fair amount of activity, the introduction of relatively unknown individuals all contributing to the same project would lower the project’s ranking. We plan to implement more techniques to aid discovery of such scenarios - stay tuned!
Observing technology trends. It is very common to observe projects become popular, and then later fall in popularity. In-line with the expansion or decline in popularity stands a migration of developers from one project to the next. With the PoD algorithm and the Trust graph, we can detect these patterns and predict technology changes and adoption using the real-world data.
Conclusion
After months of research and validation, we are now able to share the PoD Algorithm with others for review and feedback.
We are releasing the Trusty implementation of the PoD Algorithm—the “OSS Trust Graph”—initially as a private beta. We believe it has potential to help make the open source ecosystem safer, and intend to open it up more broadly—but we need to do this responsibly. Our goal is to make sure that it won’t be harmful to open source communities, or create unintended and unwelcome behaviors. We also see this as a part of a ‘multipronged’ approach to this problem space and not a panacea solution to the problem, which is why we combine the graph with other signals of potential risk.
Stacklok has a long history of acting as good custodians of open source. Our co-founders started projects such as Kubernetes and Sigstore and many others, so we always try to adhere to a community serving approach.
We believe that insight and controls around open source dependency decision making will be critical to sustainability of the communities that drive so much innovation in the software industry. As attackers become more sophisticated and have access to more sophisticated tools, we will need to come together and collaborate in an effort to drive sustainability over time.
If you’re a developer, open source contributor, or security researcher, we invite you to join our private beta. Be among the first to test this out, and let us know what you think.
We look forward to continuing to iterate and engage on this, and engaging with the broader technology and open source community to make open source software safer for everyone.
Luke Hinds is the CTO of Stacklok. He is the creator of the open source project sigstore, which makes it easier for developers to sign and verify software artifacts. Prior to Stacklok, Luke was a distinguished engineer at Red Hat.
Pankaj has over 20 years of experience in the areas of AI, ML, computer vision, cybersecurity, and software development. Prior to Stacklok, Pankaj worked as a Principal Staff Scientist for SAS, focused on cybersecurity and computer vision, where he developed ML algorithms for detecting suspicious user and device activities from network communications.